🎉 Patent Granted — Our Agentic AI Framework has been officially patented | 30th September 2025 Know More


🎉 Patent Granted — Our Agentic AI Framework has been officially patented | 30th September 2025 Know More


As Cognius.ai we are proud to say that we have built one of the most accurate NLU engines in the market. This blog post is about how we planned to achieve it.
NLU stands for Natural Language Understanding. NLUs are at the very centre of any agentic automation platform and for Cognius.ai it is no exception. In this blog post, I will be using the term NLU in the context of intent recognition. When a user engages with agentic automation (i.e., a chatbot or a voice bot), the user utterance is processed by the NLU engine and an intent is derived. Deriving an intent is nothing but a text classification. When the intent label is available, then the bot can decide where to direct the conversation. (Here we also assume a retrieval based chat or voice bot).
Text Classification is a classic machine learning task and people have mastered the art for many years. Recently, with Transformer based architectures, the accuracy has been drastically improved. But, when it comes to agentic AI, there is still a considerable gap between the industry expectations vs what the bleeding edge deep learning models can offer. If you are building a agentic automation platform, the gap widens due to inherent technical challenges linked to architectural decisions. Let us explore those now.
For many practical reasons, it is commonly seen that bot developers train NLUs for intent recognition with less data and the data could be highly imbalanced. Also, the diversity of training data in a given intent class could vary from use case to use case. Therefore, the agentic AI platform should use a number of techniques to make sure the data is properly preprocessed before any attempt of machine learning. Also, depending on the size of the dataset, different machine learning techniques should be applied.
But there is another huge challenge to overcome if we try to offer a agentic AI platform in a PaaS setup. The reason is simple. We have to centrally manage all the different use cases that the users build and host them in a way that inference happens in real-time. Most importantly, the platform’s pricing should fit into different use cases across different industries. All this pushes companies like us to host leaner deep learning models. Not only do we have to optimise deep learning models for computational efficiency, but also restrict the use of huge end-to-end models for NLU tasks.
After significant thought on this matter, we have outlined our approach to improving our current NLU performance as follows:
Improving the word embedding generation and making it robust
Lightweight decoder model trained per use case
Implementing a mechanism to reduce overfitting (not disclosing all details here as this has become the basis for one of our patents under processing)
Initial results demonstrated that our technique to reduce overfitting contributed a lot to the accuracy. We have compared our results with one of the recent benchmarking done by, MIT-IBM Watson AI Lab (“Benchmarking Commercial Intent Detection Services with Practice-Driven Evaluations”, MIT-IBM Watson AI Lab).
The following are the standard datasets used for performance benchmarking. In the literature, these datasets are the most commonly used datasets for testing intent classifications in agentic AI applications.
HINT-3 dataset
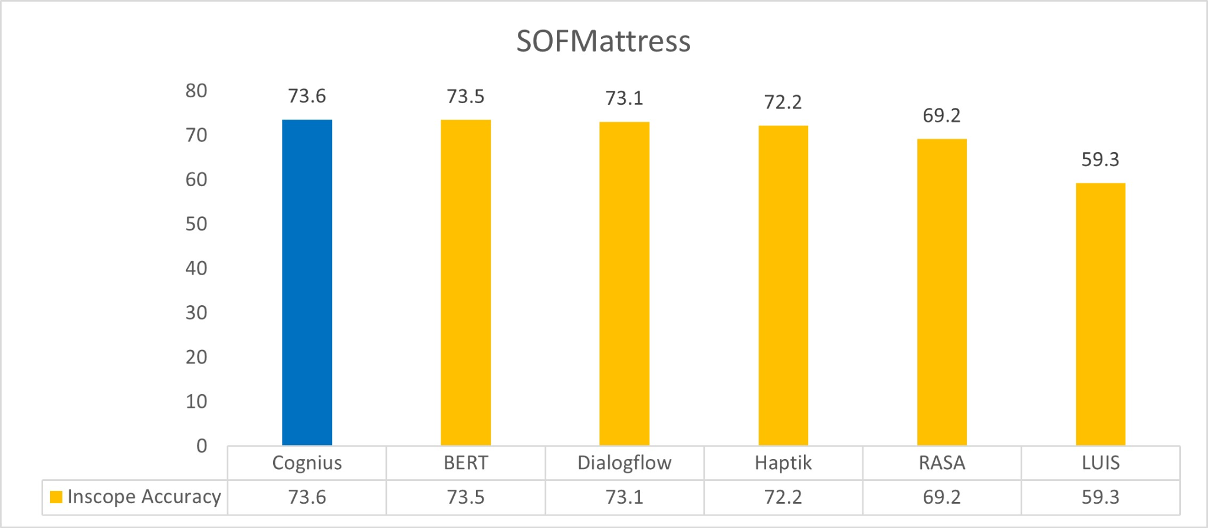
SOFMATRESS
CUREKART
POWERPLAY-11
CLINC-150 dataset
CLINC-150 TFIDF-hard dataset
HWU TFIDF-hard dataset
BANKING 77 TFIDF-hard dataset
The following are the benchmarking results for different datasets.
The datasets contain challenging scenarios simulating class imbalance and sometimes a very few data points (less than 5 data points per intent) were present under some intent classes. Cognius has demonstrated accuracy across different datasets and performed better than the competition in general. As the next steps, currently we are creating a new model that can generate robust embeddings to handle conversational noise (conversational noise can be defined as scenarios where extra phrases are present in an utterance but not contributing to alter the meaning of the utterance). We believe that our next NLU version will be able to push boundaries even further.